La serie 11×0 de Nvidia, la llamada Turing aún no ha sido oficialmente anunciada pero por lo visto ya se ha filtrado de manera vedada información de una GPU de la gama, la que vendría a ser la GT102 que correspondería a la GeForce 1180 Ti en teoría, lo cual es raro porque x80 Ti con los chips Gx102 suelen aparecer justamente entre una generación y otra y ha sido la GP102 (1080 Ti) la GPU entre «Pascal» y Volta/Turing la última en salir, por lo que la GT102 debería ser presentada después que las tarjatas basadas en el chip GT104 (1180 y 1170) y en el chip GT106 (1160 y 1150).
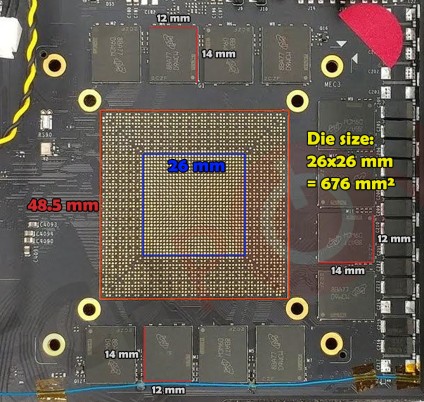
La placa no tiene montado el chip final, pero por lo visto será de unos 676mm^2 y monta unos 12 chips GDDR6 a una velocidad de 14gbps dando un ancho de banda de 672GB/s, los 12 chips marcan que estamos ante un controlador de memoria de 384 bits en total. Las especificaciones exactas de la GPU las desconocemos aunque personalmente no me extrañaría que ocurriese como con la GP102 que en algunos elementos excepto las eliminadas unidades FP64 en general las especificaciones sean las del GV100 (Volta). Es decir, que este hipotético GT102 tenga un total de 5376 Stream Processors y el enorme tamaño del chip junto a otro factores nos hace pensar que NVidia ha mantenido todos los elementos posibles incluidos los Tensor Cores.
las Gx102 son siempre GPUs con unos 6 GTC, la reducción de costes en el caso que nos ocupa vendria del reemplazo de la cara memoria HBM2 y su sustrato/interposer por la memoria GDDR6. ¿La contrapartida? Algo menos de ancho de banda respecto a la GV100, en realidad la GT102 vendría ser la nunca lanzada GV100… ¿Pero a que viene el cambio en la nomenclatura? ¿Como es que Nvidia no habla de la serie GV? No lo sabemos, pero la explicación la podemos encontrar en la GPU del Tegra Xavier cuya organización interna es distinta a la de Volta.
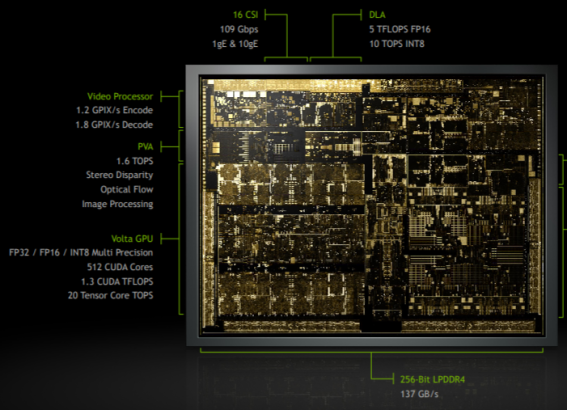
¿Cuales son los cambios? La supuesta «Volta» en Xavier tiene el doble de rendimiento en los Tensor Cores que lo que le pertocaria si la configuracion interna fuese como en la GV100. Pero lo que llama poderosamente la atención es un detalle de la GPU dedicada en el Drive Pegasus que tiene que acompañar al Tegra Xavier.

Supongamos que las GPUs dedicadas corren a la misma velocidad de reloj que la GPU en el Tegra Xavier y que ambas GPUs dedicadas son identicas. De los 320 TOPS hemos de restar unos 40 TOPS de ambos Xavier, esto deja unos 280 TOPS que hace que cada GPU se quede con unos 140 TOPS y por tanto 7X. Dado los Tensor Cores y las Unidades CUDA se encuentran en el mismo «complejo» entonces acabaríamos teniendo unas 3584 unidades CUDA, se que no coincide para nada con la GT102 que he comentado antes, pero en realidad estaríamos hablando de la misma familia de GPUs.
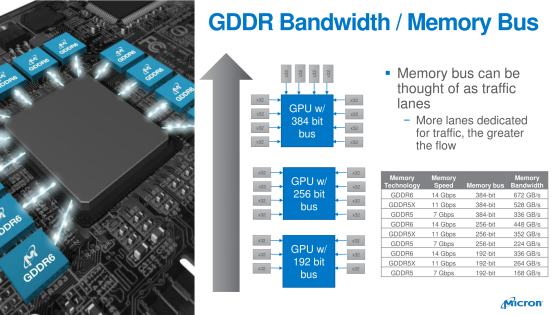
¿El motivo? Pues que estariamos hablando de la GT104, con unos 4 GPC y un bus de 256 bits GDDR6 que sería la GeForce 1180 estandar. Cada GPC de la gama GT10n donde n sería un número par (GT102, GT104 y GT106) tendría unos 896 nucleos CUDA por GPC. La GT102 tendría 6 GPC y por tanto unos 5376 núcleos CUDA, la GT104 tendría unos 4 GPC y por tanto unos 3584 núcleos CUDA y la GT106 unos 3 GPC y por tanto unos 2688 núcleos CUDA. Las configuraciones de memoria serían de 384 bits, 256 bits y 192 bits cada una y todas utilizarían memoria GDDR6. ¿Y de donde saco la posible configuración de la GT106? Ejem… Pues de esta diapositiva del fabricante de memoria Micron y es que por lo visto la serie GeForce 11 será la unica gama de productos con memoria GDDR6 que saldrá este año en el mercado.
Ahora bien, lo de los Tensor Cores se ha de aclarar. ¿Que utilidad tienen? ¿Son parte imprescindible de cara al futuro en el hardware gráfico para juegos? Por el momento la única utilidad de los Tensor Cores es para realizar una función que es el denoiser y Nvidia quiere utilizarlos de cara a extensiones para el DirectX Raytracing, pero no son esenciales para el mismo.
 DXR es una API completamente agnóstica de fabricante por lo que los Tensor Cores que por el momento son only Nvidia son una forma de atar los juegos a sus GPUs que es lo que ha sido siempre Gameworks. Aquí Nvidia nos da mucha más información en que consiste:
DXR es una API completamente agnóstica de fabricante por lo que los Tensor Cores que por el momento son only Nvidia son una forma de atar los juegos a sus GPUs que es lo que ha sido siempre Gameworks. Aquí Nvidia nos da mucha más información en que consiste:
Para permitir que los desarrolladores de juegos tomen ventajas de estas nuevas capacidades, Nvidia tambien anuncio que el SDK NVIDIA GameWorks añadira un ray-tracing denoiser module.
Más abajo podemos leer:
El Ray Tracing Denoiser es un conjunto de librerías, que permiten un rápido ray tracing a iempo real utilizando técnicas de eliminación de ruido. Esto incluyen algoritmos para ray traced area lights, glossy reflections y ambient occlusion. Con una cantidad de baja de muestras por pixel, puedes conseguir rápidos resultado de alta calidad para los reflejos entre ojbetos, contact hardening de alta calidad y soft shadows sin los artefactos de los efectos de posprocesado a nivel de pantalla.
De esto hablo Nvidia en la pasada GDC concretamente, el video es muy técnico pero es para que veaís que no me lo saco de la manga.
¿De donde viene esto en origen? En el pasado SIGGRAPH, que se celebro en Agosto del año pasado, Nvidia presento una utilidad para los Tensor Cores basada en poder realizar una variación del Ray Tracing del tipo Montecarlo (Con iluminación indirecta dinámica tanto difusa como especular), en realidad el método utilizado era lo que llamamos Path Tracing para diferencialo de Raytracing tradicional. ¿La particularidad del Path Tracing? La cantidad de muestras por pixel necesarias para que se vea bien.

Cuantos menos muestras más ruido, el siguiente gif de la versión «Path Tracing» del antediluviano Quake 2 lo explica a la perfección cual es el problema.
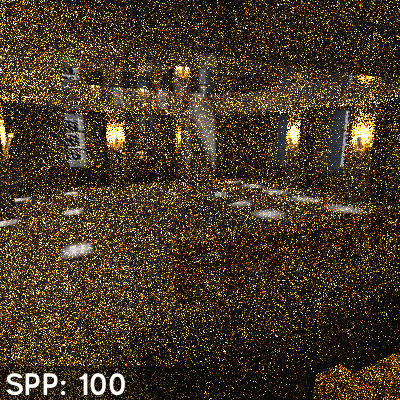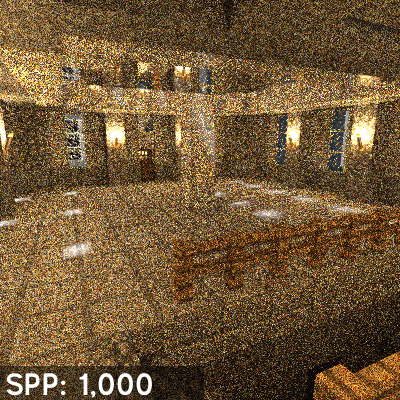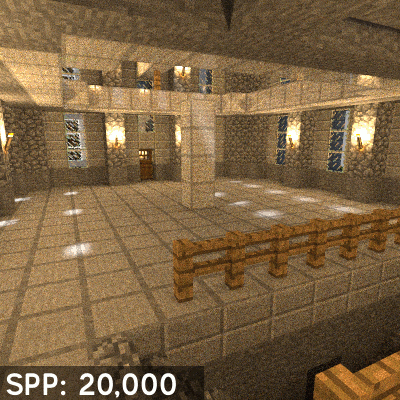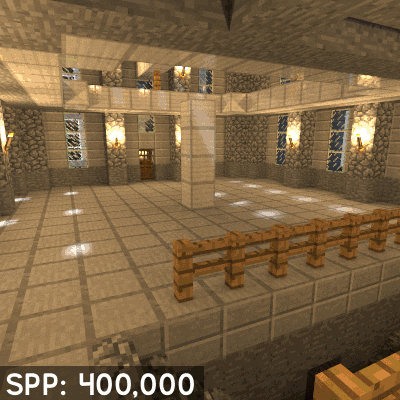
Y es aqui donde entran los Tensor Cores, estos permiten conseguir una mayor calidad de imagen con pocas muestras. Pero se ha de aclarar que la situación en la que nos encontramos no es la de renderizar la escena por completo via Raytracing sino utilizarlo de cara al Raytracing híbrido. La idea es que para cosas como la generación de sombras, reflejos e incluso el Ambient Occlusion via trazado de rayos son necesarios también grandes cantidades de muestras para un buen resultado y una capacidad de computación enorme, pero con los tensor cores y un algoritmo de Inteligencia Artificial aplicado la cantidad de muestras necesarias se reducen enormemente y con ello se acaba necesitando menos potencia de computación. La contrapartida es que el eliminador de ruido depende de la potencia de los Tensor Cores, de ahí a que Nvidia en Turing en teoria haya duplicado el ratio de los mismos respecto a Volta.
En todo caso las GeForce 11 son una Stop Gap Solution, las GeForce 10 son suficientemente buenas pero Nvidia necesita tomar ventaja de su tecnología en el mercado doméstico lo más rapido posible. AMD que es la competencia directa no tiene nada que pueda contrarrestar esto, pero una cosa que tengo clara es que las GeForce 11 serán caras. ¿7nm? Lo dudo, eso va a ser para el año que viene y tengo muy claro que será para la GeForce 12 que será una version de la serie que estamos hablando a 7nm. Es más no me extrañaría que la GeForce 11 en comparación con generaciones anteriores tenga una vida más bien corta en el mercado, el motivo de ello es que se va a llegar a la madurez del proceso de 7nm el año que viene, lo que llevará al lanzamiento de la gama GeForce 12. ¿Tenemos algunas pistas de ella? Bueno, no muchas pero…
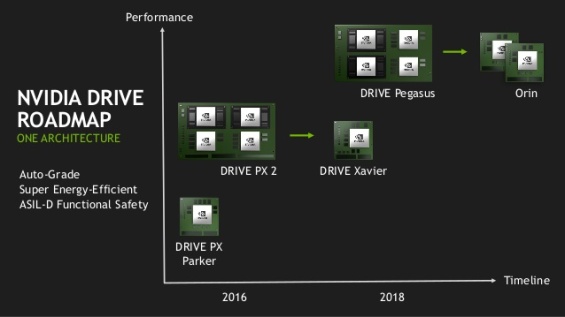
Nvidia va a lanzar el Tegra Orin el año que viene que incorpora en un solo chip Xavier+GT104 por lo que pasaríamos a tener un SoC con una GPU de 160 TOPS/4096 núcleos CUDA para una posible (no lo sabemos) configuración de 4 GPC y 256 bits GDDR6 para ser la Geforce 1280, la cual se fabricará a 7nm. ¿Pero que sentido tiene que la GeForce 1280 sea el siguiente Tegra si es para dos mercados distintos? Por lo que se ve a partir de 2020 quieren abandonar el clásico front-end/planificador de las GPUs basado en un microcontrolador en tener un sistema complejo que gestione de manera autonoma las listas de pantalla y de computación y de ahí la idea de colocar varios núcleos de proposito general. Arquitecturalmente es un overkill pero las GPUs actualmente van tan sobradas para el rendering tradicional y las cosas se han estancado tanto que se hacen posibles estas cosas. ¿Que colocar una CPU completa en la GPU solo para gestionar las listas de pantalla y computación no aumenta los costes? Pues la ponemos y ya esta, claro esta que todo lo referente a la GeForce 12 es por el momento algo muy lejano.
En cuanto al tema economico, y con esto termino, tiene sentido para Nvidia que en vez de tener varios chips distintos para diferentes mercados tengan un solo chip universal. Así Orin/GeForce 12 se comportaría de una manera u otra según el sistema en el que estuviera colocado. Nvidia puede vender el mismo chip para diferentes a diferentes clientes potenciales para diferentes soluciones. Incluyendo una potencial consola de videojuegos de sobremesa. Pero con esto tengo muchas dudas por lo que…

En todo caso el mayor cuello de botella de las GPUs contemporaneas esta en el front-end que muchas veces no puede gestionar los cientos e incluso miles de hilos funcionando en el sistema. Por lo que las GPUs a medio plazo van a tomar ese camino en cuanto a su diseño.
Eso es todo, ahora si que he terminado.

entonces orin seria un posible dock para la switch siendo sobremesa o simplemente un cambio de cpu gpu para que llege a los tan deseados por algunos 1080 a 60 fps por que por lo comentado en otros posts ps4 y scarlet seguramente diraran de amd
Me gustaMe gusta
No recuerdo si era amd o nvidia, supongo que amd porque es mas cpu dependiente, pero creo que es la cpu la que crea esas listas, en todo caso sería engordar el procesador de comandos a lo bruto en la gf12
En amd si la cpu es potente, de gama alta, podría cundir mas que un arm generando comandos o un generador actual
Me gustaMe gusta
https://hardzone.es/2018/02/21/amd-ryzen-embedded-v1000/
urian parece que amd ya tiene algo con un consumo similar cuando funcione a minimo rendimiento entre 12W y los 45W
Me gustaMe gusta
888 casino online
hypercasinos
wildhorse resort casino
harrah’s online casino
free casino games no download no registration
Me gustaMe gusta