#1 El problema del overdraw
Uno de los mayores problemas con el que tradicionalmente se han enfrentado las GPUs es el overdraw, esto lo comente en una entrada hace tiempo pero es importante repasarlo para entender el contexto y la utilidad de lo explicado en la patente a la que voy a hacer referencia en el segundo apartado. el problema del ovedraw lo explique en una entrada en concreto hace un tiempo que os recomiendo leer para entender la utilidad de lo discutido en esta entrada.
Esta es otra de las piezas de función fija cuya utilidad y funcionamiento es descrito en una patente de AMD y que no hemos visto aplicada en ninguna de las GPUs de AMD que hay en el mercado y que bien podríamos ver en PS5 (y Xbox Scarlett), se trata de un cambio en la GPU, más concretamente en su bloque principal que es el GFX, en el caso que nos ocupa estaríamos hablando del GFX10. La nueva pieza tiene que ver con el Culling de fragmentos que es una forma de evitar el overdraw y el excesivo uso inutil de la tasa de relleno, así como la reduccion de cálculos inutiles durante la etapa del Pixel/Fragment Shader.
#1 Explicación
Voy a tomar como referencia y por tanto como fuene principal la patente de AMD titulada «Out of order Pixel Shader Exports«. De la cual de entrada nos centraremos en la FIG.3 de la misma.
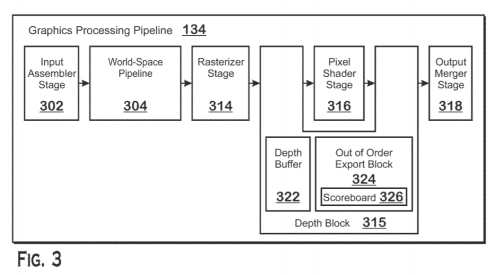
La FIG.3 nos describe de manera ordenada las diferentes etapas del pipeline 3D convencional, siendo el World Space Pipeline la parte de la etapa geometrica, por lo que de entrada hay que aclarar que todo lo descrito en esta entrada es post-rasterizado y no se debe confundir en ningún momento con ya comentado Next Generation Geometry Pipeline relacionado con los anunciados pero aún no implementados Primitive Shaders.
El elemento adicional es uno llamado Depth Block que es invocado dos veces en el pipeline, una después del rasterizado y la otra después del Pixel/Fragment Shader pero antes de enviar el resultado a los ROPS por lo que podemos suponer sin equivocarnos que es una pieza adicional en el Shader Engine que no corresponde a las vistas hasta ahora y seria junto al Primitive Assembler descrito en algunas entradas anteriores de ste blog una unidad nunca vista en una GPU de AMD, ni en la GFX9 y podría formar parte de las GFX10 (Navi) y por tanto terminar en la siguiente generación.
El Depth Block es descrito de la siguiente manera:
El Depth Block 315 realiza z-culling para eliminar los fragmentos que se ven ocluidos por otros fragmentos ya procesados por Depth Block 315, el Z-Culling es realizado bandose en el valor de profundidad de los fragmentos. Para realizar el Z-Culling, el Depth Block 315 almacena un bufer de profundidad 322. Dicho bufer almacena los valores de profundidad de los fragmentos procesados por el Depth Block 315. Este compara los fragmentos que le llegan de la etapa de rasterizado con los valores almacenados en el búfer de profundidad 322 para determinar si el fragmento pasa el test de profundidad, si el fragmento pasa el test de profundidad este no es recortado y se continua el resto del pipeline de procesamiento gráfico. Si el fragmento no pasa el test de profundidad este es recortado (y por tanto no pasa a la siguiente etapa).
La clave aquí es un un bufer de profundidad y no el bufer de profundidad. Esto es importante porque sería imposible colocar todo el búfer de profundidad a nivel de pantalla dentro de la memoria interna del chip que es donde se encuentra el Depth Block. Esto no tiene nada de especial y lo hemos visto en multitud de GPUs durante la historia. ¿La única manera en la que puede hacer esto? Pues almacenando bufers de profundidad de los diferentes tiles que componen el búfer de imagen final, pero esto es algo que un Inmediate Renderer (no-tile) no puede hacer a no ser que rasterice por tiles, en realidad ya tenemos un rasterizador por tiles en AMD a partir del AMD Vega.
En la implementación actual a nivel de PC (Vega en el caso de AMD y Maxwell en adelante en el caso Nvidia) el rasterizador/DSBR escribe los fragmentos resultantes en la Cache L2 pero en el escenario descrito por la patente es mucho más parecido a un Tile Renderer a la hora de almacenar el Z-Buffer ya que lo hace a nivel de Tile y en una memoria interna aparte, por lo que lo podemos considerar como una implementación más avanzada y cercana a lo que es un Tile Renderer pero sin llegar a serlo. El hecho de que sea una evolución marca que ha de ir a parar a un hardware una generación por encima de Vega por lo que estaríamos hablando de uno de los añadidos para el GFX10 (Navi). Aunque en realidad no elimina el Z-Buffer general, si que lo utiliza a nivel de Tile para el proceso de eliminación de los fragmentos no visibles por el hecho de estar ocluidos por otros en la misma posición.
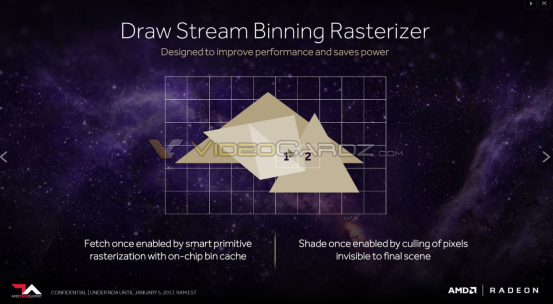
Por la diapositiva de AMD sobre Vega lo primero que nos viene a la cabeza es que la funcionalidad del Depth Block esta ya integrada en Vega, pero esta diapositiva es de la primera presentación de Vega y dicha funcionalidad no se encuentra mencionada en el hardware final, lo cual es un caso muy similar al del NGG y los Primitive Shaders.

El Depth Block por lo tanto es de esas cosas que AMD no pudo implementar por falta de tiempo en Vega pero el planteamiento en la patente va más allá porque no hace referencia solo de hacer Culling post-rasterizado sino tambien post-Pixel Fragment Shader (texturizado). La patente llama al primer caso Early Z Culling y al segundo Late Z Culling

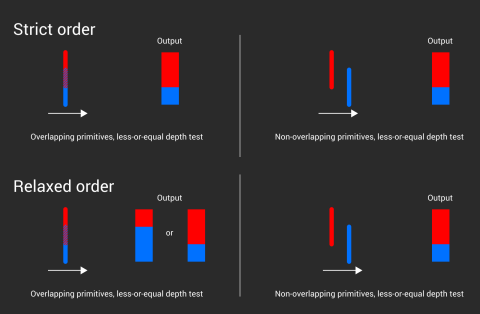
Como hemos visto antes en la cita de la patente, con Z-Culling la patente se refiere a que se eliminan todos los fragmentos que se ven superpuestos por otro fragmento, en el Early Z Culling donde no sabemos el color de los fragmentos y si son o no transparentes o semitransparentes, el hecho de aplicar el Z-Culling sería contraproducente por lo que de entrada el Late Z-Culling sirve para esos fragmentos con textura transparente o semi-transparente que pueden ser marcados de alguna manera durante el test de profundidad para que no lo tengan que realizar. ¿El truco que se intuye de la patente? Que la GPU deje pasar ciertos fragmentos en concreto antes y haga el proceso completo con estos en vez de seguir el orden de renderizado marcado por la lista de pantalla, de esta manera para esos fragmentos y solo para esos fragmentos se texturiza y se aplican los efectos para luego seguir el camino marcado por la API.
Para ello la GPU necesita dos elementos que son esenciales, el primero de ellos esta en la misma patente.
El Depth Block 315 también incluye un out of order export block 324 que incluye un scoreboard 326. El out of order export block 324 facilita el orden de exportación fuera de orden desde la etapa del Pixel Shader 316. Una exportación ocurre cuando la etapa Pixel Shader 316 completa el procesamiento para un fragmento en las unidades de procesamiento en paralelo 202 (por ejemplo, determinar el color del fragmento) y envia los pixeles (ya procesados) a las unidades de procesamiento en paralelo 202 para un procesamiento adicional por el resto del pipeline de procesamiento gráfico 134.

Las unidades en paralelo 202 son las Compute Units, esto significa que la Compute Unit a través del Export Bus de la misma envia los datos de la Cache L1 de Datos/Texturas hacía otra Compute Unit (Post-procesado via Compute Shaders) o a las unidades RBE dentro del mismo Shader Engine.

Pero si hacemos caso a la patente la exportación se puede hacer directamente al Depth Block, lo que marca que estos se encuentran en el mismo Shader Engine
Especificamente, la etapa Pixel Shader 316 puede actualmente querer completar los fragmentos en un orden diferente al de la API. Por ejemplo, la etapa Pixel Shader va a querer completar un fragmento más nuevo primero que otro más viejo. En un enfoque, la etapa Pixel Shader 316 puede «sujetar» los fragmentos más nuevos hasta que los más viejos completen el procesamieto, entonces exportar los fragmentos más viejos y luego los mas nuevos con tal de mantener el orden de la API. Este enfoque de «sujección» requiere al menos algún búfer de memoria para almacenar los valores fuera de orden.
El planteamiento de dicho bufer ya lo hemos visto en otros sistemas gráficos, es el llamado Pixel Local Storage que nos da una memoria intermedia entre el Pixel/Fragment Shader y los ROPS.
![]()
![]()
Pero el PLS es producto de tener el Color Buffer al igual que el Z-Buffer a nivel de Tile en la propia GPU y poder hacer bypass a los ROPS/Blending. No es el caso que nos ocupa.
Por lo tanto, en otro enfoque, en lugar de usar un búfer para mantener el orden de API para las exportaciones del Pixel Shader, el out of order export block 324 incluye un scoreboard 326 para ayudar a permitir las exportaciones fuera de orden desde la etapa Pixel Shader 316
Es decir, que en el planteamiento de AMD sugerido en la patente no tenemos una unidad PLS como ya he especificado antes.
El out of order export block 324 incluye un scoreboard 326 que almacena las marcas de tiempo de los fragmentos que han sido o están siendo procesados por la etapa pixel shader 316.
…
En referencia a la FIG. 5 el out of order export block 324 actualiza el scoreboard 326 basandose en los fragmentos recibidos de una etapa anterior en el pipeline de procesamiento gráfico 134 (por ejemplo la etapa de rasterizado 314). Actualizar el soreboard supone actualizar las marcas de tiempo 504 basadas en los fragmentos recibidos. Más especificamente, por cada posición de pantalla, el out of order export block 324 actualiza la marca de tiempo del fragmento 504 para esa posición de pantalla reflejando el nuevo fragmento,en orden de la API, que esta siendo procesado o ha sido procesado previamente por la etapa Pixel Shader 316. por lo tanto, cada marca de tiempo de fragmento 504 incluye una posición de pantalla y la marca de tiempo del fragmento más nuevo encontrado en esa posición. En algunos ejemplos, la marca de tiempo es un identificador numérico relativo a la orden de la API con el número más bajo indicando un nuevo fragmento siguiendo el orden de la API.

Es decir, el Scoreboard no sirve como PLS sino que simplemente sirve de cara al Culling, en realidad sirve para los fragmentos con texturas transparentes ya que el realizar Culling antes del Pixel/Fragment Shader es contraproducente con ese tipo de fragmentos ya que en dicha etapa la GPU no sabe si son transparentes o semi-transparentes. Mantener los fragmentos de una posición de pantalla concreta a la espera de ser eliminados incluso si no pasan el test es importante de cara a poder aplicar el Culling en escenas con fragmentos transparentes sin tener que hacer el truco de renderizar la escena dos veces (una para superficies opacas y otra para superficies transparentes). En este caso los fragmentos no salen en orden estricto y el test de profundidad no se ejecuta durante la fase previa al pixel/fragment shader.
¿Su utilidad más allá de eso? Hay escenarios donde el pipeline gráfico no se utiliza para renderizar una escena que no vamos a ver en pantalla, como es la generación de los mapas de sombras (donde la escena se renderiza desde la posición del emisor y generando un Z-Buffer desde su posicion) y en la creación del G-Buffer en el caso del renderizado por diferido.
No obstante realizar Culling a nivel de GPU es algo que aunque parezca trivial no se podía hacer en un Inmediate Renderer hasta hace poco. El motivo por el cual las técnicas de Culling se ven en los Tile Renderers es porque los Tile Renderers al contrario de los Inmediate Renderers tienen la capacidad de crear listas de pantalla después de la geometría, una por cada tile, pero no lo hacen a mitad del renderizado del fotograma.

Para entendernos mejor tradicionalmente ninguna GPU puede manipular la lista de pantalla en medio del renderizado, como mucho lo que podían hacer las GPUs en su día era añadir listas de comandos a posteriori, tened en cuenta que las listas de comandos antes eran como un anillo/cola del tipo FIFO donde los elementos nuevos se colocan al final de la cola.

Si hacemos Culling a mitad de un fotograma estamos manipulando en el fondo la lista de comandos generada por la API ya que tenemos que eliminar en ella todas las referencias a los fragmentos eliminados. Ya no podemos tratar a la lista de comandos como una pila. Precisamente, en las APIs pre-DirectX 12/pre-Vulkan la manipulación de la lista de comandos para ir eliminando las referencias a los elementos descartados supone que sea la CPU la que elimine de la lista los comandos correspondientes a la geometria y esto supone tener que parar por completo el pipeline gráfico por completo y dado que habitualmente los Inmediate Renderers (No-Tile Renderers) no almacenan la información de la geometria esto significa volver a reiniciar el pipeline gráfico de nuevo aparte del tiempo en que la CPU se pase eliminando los comandos relacionados con los elementos no visibles o simplemente marcando estos con un bit especial que los permita descartar.
¿Cual es la solución a este problema? Dejar que sea la GPU la que pueda manipular la lista de comandos el vuelo, habitualmente lo puede hacer de manera convencional pero añadiendo los comandos al final de la cola cuando en algunos casos lo ideal sería que pudiesen insertarse o eliminarse de la lista de comandos y que esta sea tratada no como una pila FIFO sino como una lista enlazada.
Pues bien, en estos casos y para evitar que la CPU tenga que intervenir AMD a partir de Polaris añadio una pieza adicional llamada Hardware Scheduler (HWS). La cual fue implementada a nivel de PC en Polaris y en consolas esta implementada solo en Xbox One X.

El Early Z Culling y el Late Z Culling son posibles sin perder rendimiento gracias al HWS, pero no es el HWS la pieza que lo hace sino que lo único que permite es manipular la lista de comandos el vuelo. Pensad que la GPU no sigue más que la lista de cosas a hacer que le va mandando la CPU que es creada por la API en el orden establecido y normalmente los fragmentos se procesan en un orden estricto, es por ello que el hecho de variar el orden de renderizado necesita marcas de tiempo, es decir, el HWS crea una lista de dibujado aparte cogiendo una serie de fragmentos que nos interesa que sean texturizados primero pq nos interesa al ser transparentes y los re-inyecta después de que al resto se le ha hecho el Early Z Culling y esto lo hace en combinación con el Depth Block que he descrito antes.
#3 Checkerboard Rendering
Una de las particularidades de la patente es que el Scoreboard de cada fragmento no solo apunta la profundidad sino también su posición en pantalla, lo cual en parte es ideal para la implementación del Checkerboard Rendering de manera automatizada dejando libre por completo el octavo Render Target y sin tener que depender del Color Buffer que es como esta implementado en PS4 Pro donde el proceso de generación del Checkerboard pese a estar automatizado a nivel de API no lo esta a nivel de hardware, dependiendo del pipeline de computación para ello.

Aunque hay gente pidiendo 4K nativos para una mejora en la calidad visual es preferible el uso del 4KCB porque permite aplicar el doble de operaciones por pixel que en los 4K convencionales haciendo que la escena sea visualmente más compleja que con los 4K nativos, aunque esto ya lo he hablado varias veces en el blog y seria repetirme mucho de lo dicho en otras entradas.
¿La clave de todo ello? En el caso de PS4 Pro (y supongo que Xbox One X) tienes que adaptar el juego a través de un parche para que soporte el ID Buffer, en el caso que nos ocupa si el Checkerboard es generado automaticamente por la GPU independientemente del juego es posible (y esto por el momento no lo se) que Sony (y Microsoft) hayan movido el proceso de reconstruccion en el Checkerboard de los Shaders a una unidad de función fija pero no tengo referencias a la pieza que nos falta en ese aspecto. Pero la lógica me dice que de cara a la siguiente generación van a querer descargar las unidades encargadas de ejecutar los shaders de ciertas tareas repetitivas con tal de que se aproveche su potencia en otras cosas.
Y con esto termino, ya sabéis que tenéis los comentarios de esta entrada y el Discord.

muy buena entrada, gracias como siempre
«Aunque hay gente pidiendo 4K nativos para una mejora en la calidad visual es preferible el uso del 4KCB porque permite aplicar el doble de operaciones por pixel que en los 4K convencionales haciendo que la escena sea visualmente más compleja que con los 4K nativos, aunque esto ya lo he hablado varias veces en el blog y seria repetirme mucho de lo dicho en otras entradas.»
podrias hacer un post, explicando esto de la escena mas compleja, de forma mas consisa , ya que esta la gente con el 4k nativo que se ve mil veces mejor.. cosa que yo no lo veo tan asi… mas nitido si, porque hay mas puntos base por decirlo de forma bruta e inculta en estas cosas.. pero el poder tener un juego de calidad casi 4k nativos con casi la mitad de potencia no tiene precio y creo que la gente no aprecia esas cosas.. y la gente esta que si se ve un pelo menos en las pestallas de un personaje ya pone el grito en el cielo
saludos
Me gustaMe gusta
Como tú con la Switch.
Me gustaMe gusta
si, estas entradas de cómo funcionan las cosas son adictivas.
¿el CBEA puede hacer ese nivel de culling o hacerlo casi completo modificando las listas de pantalla decalguna forma?
Doy por supuesto que juegos del nivel de uncharted 2 y 3 y killzone 2 se aplica.
Y ya lo pregunto aquí: ¿como se aprovechan los ciclos muertos en gpu’s tipo Xenos/RSX si no tienen pipeline de computación ni pueden recibir tantas listas de pantalla como una gpu DX12?
Me gustaMe gusta
¡¡me han cambiado mi carismático ñeco amarillo por uno de un vampiro rabioso!!
Me gustaMe gusta
He sido yo.
Me gustaMe gusta
Vale, estás perdonado, jijijijijiji
Me gustaMe gusta